Data Factory: Importing multiple files with transformations
Let's assume you have a folder containing a bunch of files that you need to import somewhere. e.g. a database or another file store, and in the process of doing that you also need to transform the data in some sort of way.
One option would be to use a pipeline activity like Get Metadata to get your list of files, a ForEach to loop through them and a Mapping Data Flow within the for each to process each file.
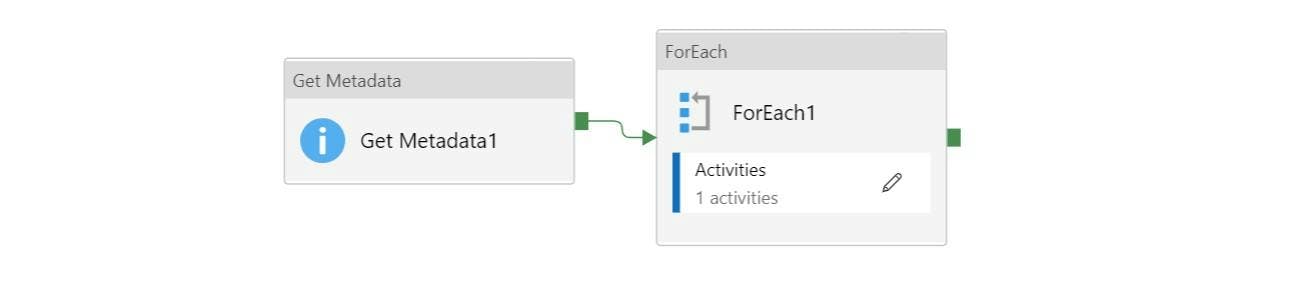
This all sounds quite reasonable, but there's a catch. Each time we use a Data Flow activity, that activity will spin-up a Azure Databricks environment to run the Data Flow. So if you have 100 files to import, then that's 100 Databricks environments that will get created.
An alternative is to do everything within one Data Flow activity, resulting in just one Databrick environment being created.
One Data Flow
In your dataset configuration specify a filepath to a folder rather than an individual file (you probably actually had it this way for the Get Metadata activity).
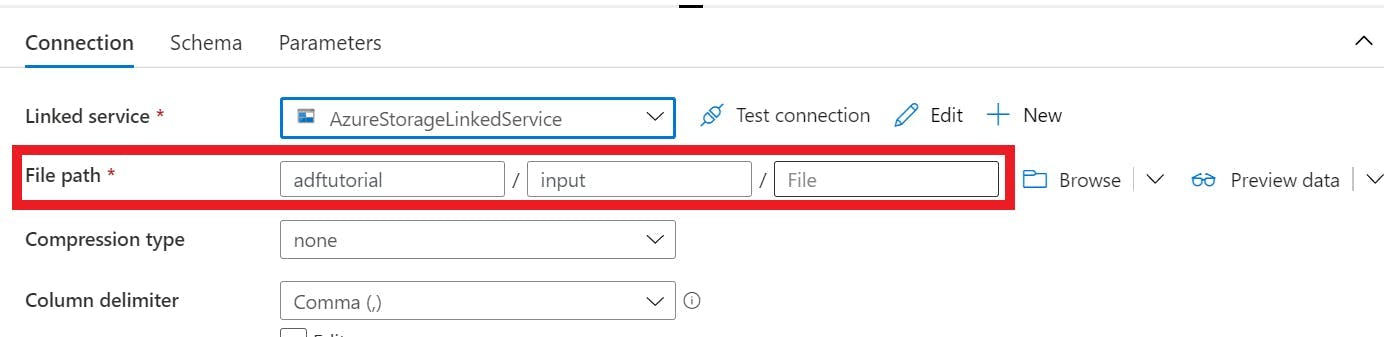
In your data flow source object, pick your dataset. In the source options you can specify a wildcard path to filter what's in the folder, or leave it blank to load every file.
Now when the source is run it will load data from all files.
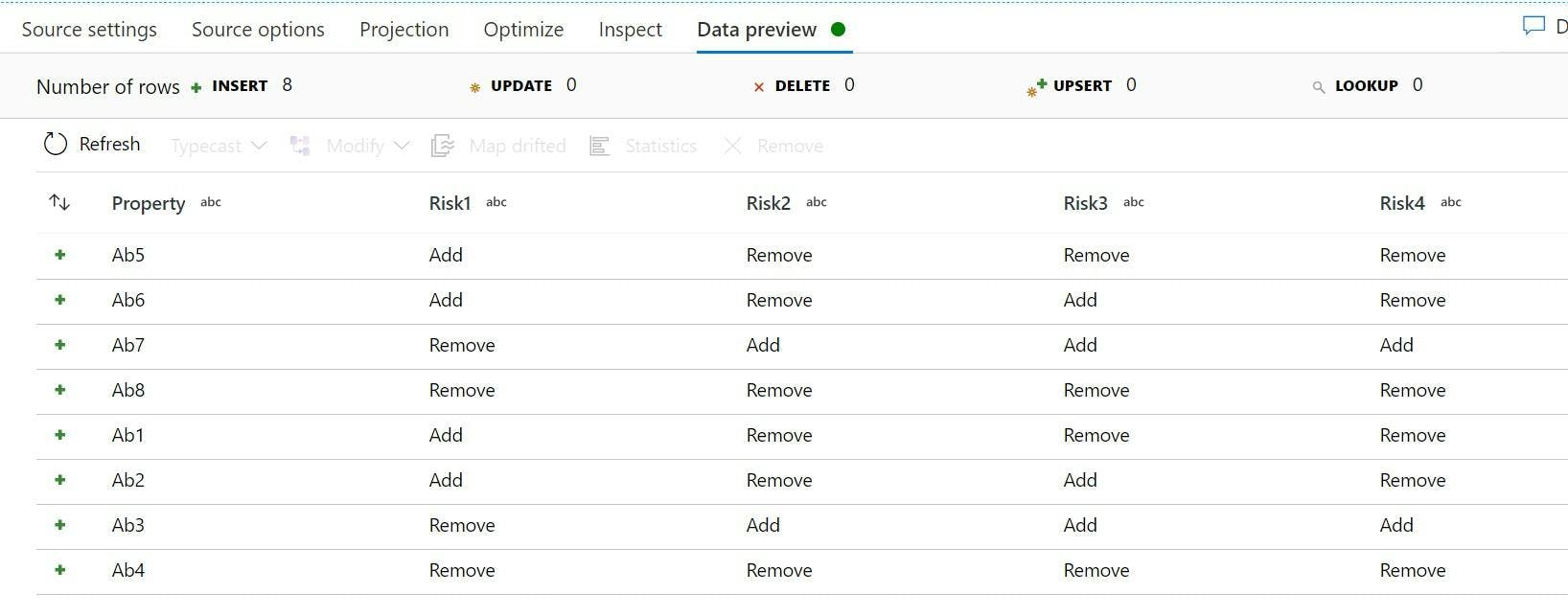
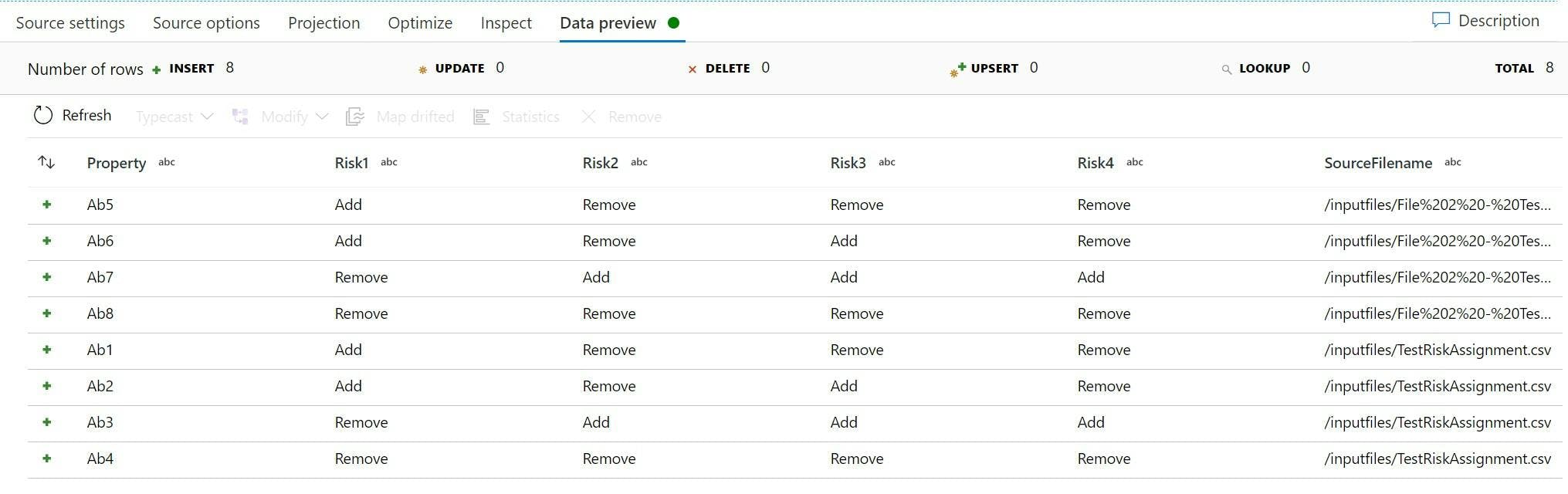
One major difference to note is now rather than iteratively going through each file we're loading them all in one go which changes how you may think of things.
If you need to know which file a particular row came from then the source options has a field where you can specify a column name for the file to be added to.
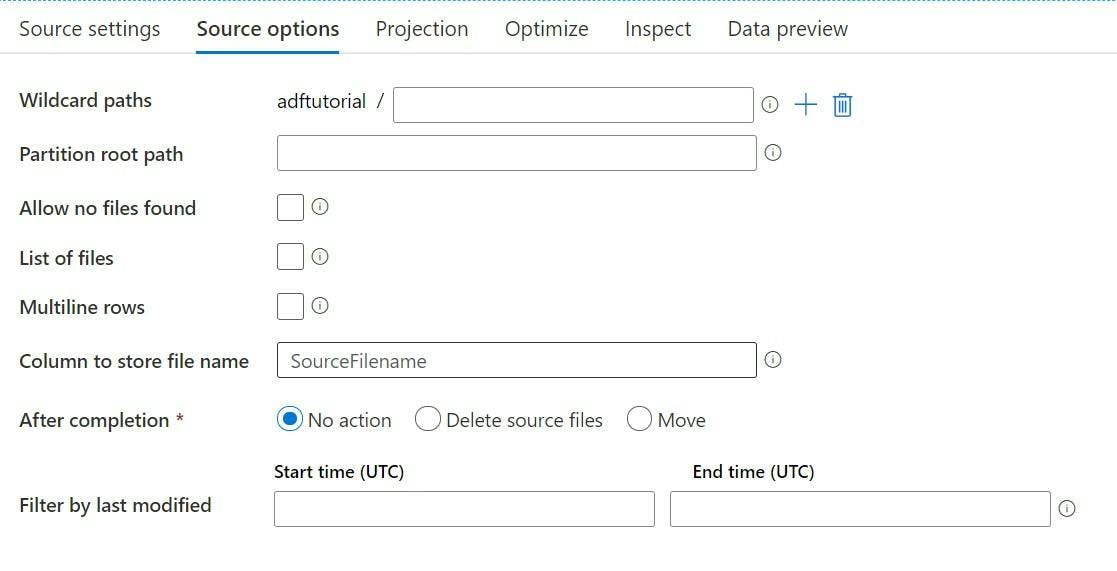
Your data now includes data from every file, and the filename it came from.