This year Sugcon came to London which given that's where I'm based is awesome for me. In total it was a 3 day conference starting with Sitecore Experience aimed more at marketers than developers. As a developer I only went to the 2 developer days, so for your benefit here's a summary of everything I saw.
Day 1
Day 1 started with a keynote, sadly life got in the way and I missed the first few hours. I'm told it was good though.
After that the day was split into a mix of sessions in the big room for all and smaller break out sessions where you could pick 1 of 4 to attend.
JSS Immersion - Lessons learned and looking ahead with Anastasiya Flynn
To kick things off I went to a talk on JSS, mostly because JSS is a subject I know very little about. This was something that became even more apparent as the talk went on! At the end of it I came away with an appreciation that I need to invest some time in learning a lot more, but my other take away was a few links on things that will help me out if I ever try some React stuff.
https://www.styled-components.com
https://www.react-spring.io
PAAS It on: Learning's from a year on Sitecore with Criss Titschinger
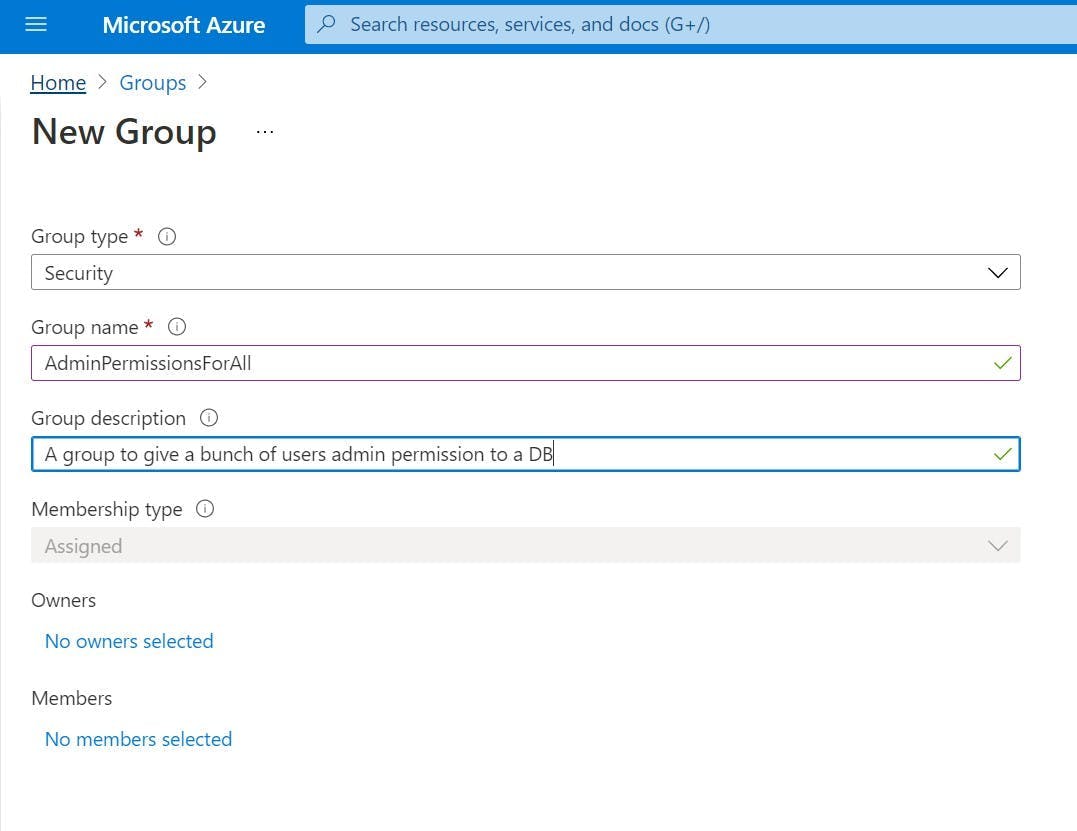
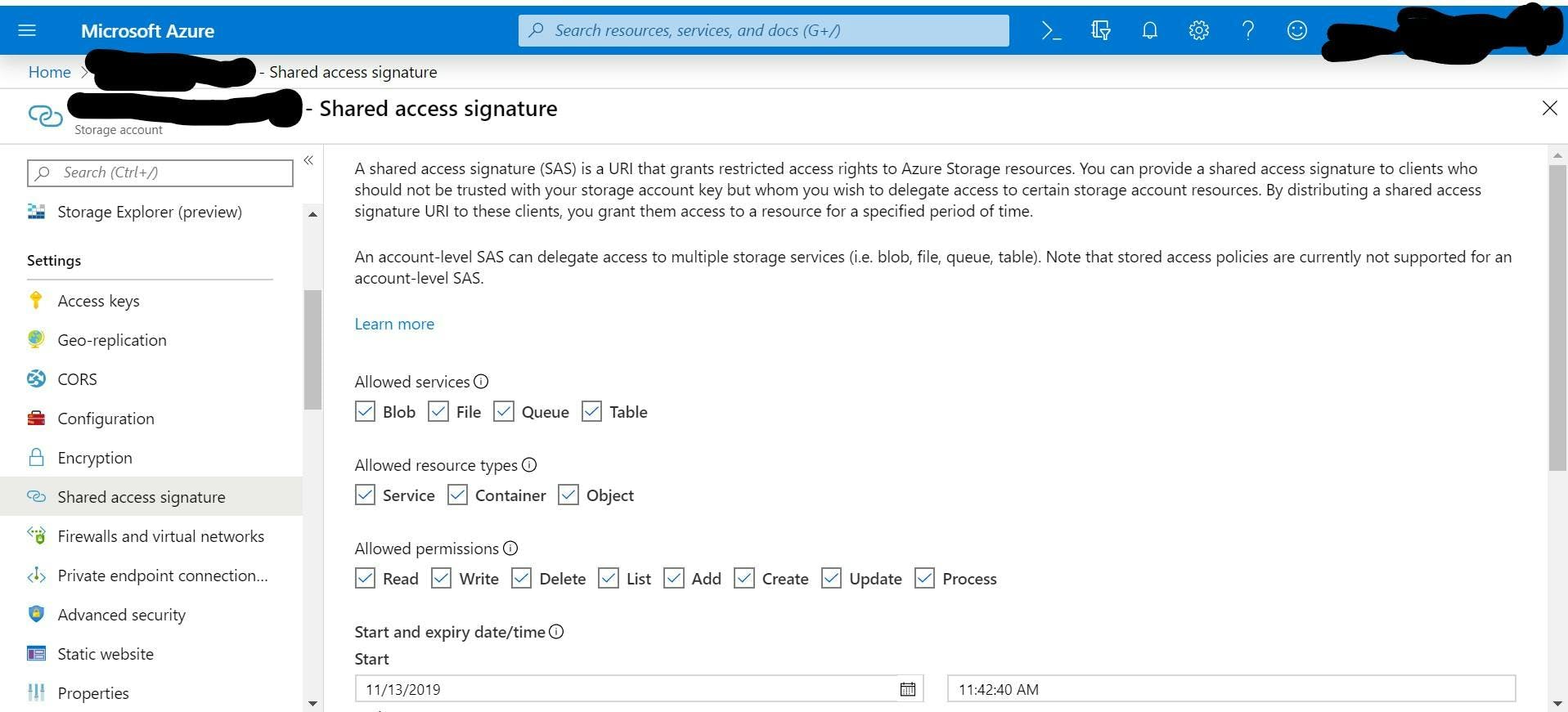
Criss works as a dev opps person and over the last year went on the journey of having a Sitecore 8.2 install upgraded to 9 using a fully cloud architecture in Azure.
Overall his experience sounded positive but he did have a few warnings from pain he experienced:
- Beware of cold start up times with web apps. These can be a real performance hit, especially when Azure decides its going to move your web app instance
- Web app slots share processing usage so when your warming one up, your live one is taking a hit. If you run on the edge of capacity, this will be an issue
- Azure search is easy to install but it has a field limitation of 1000 to watch out for
- Data migration in an upgrade takes a long time the second time. It took 9 days to migrate a years data from mongo! Only do it once.
- Run your upgrade on clean instances and do the code in visual studio.
- Web apps need to be on the premium service plan. The others are to weak
- Use elastic pools for your database to save money. The microservice architecture introduces a LOT of new dbs which are going to cost money in azure resources. Most of the time they also don't do that much so put them in a pool to share resources
- Moving to 9 is going to increase hosting charges. Be honest with clients about it.
Day 2
On Day 2 I got to attend from the start so it was a much fuller day for me.
10x your Sitecore development with Mark Cassidy
The day started with a talk on questioning how long it should take to build a Sitecore site. It was a question that never really got answered but the main thing Mark really raised was, do we over engineer what we do and would simpler actually be enough? He went on to show a time lapse video of himself implementing a bootstrap template in Sitecore which took 15 hours.
To build this site he didn't install any modules (no glass) and used just the standard Sitecore api. As he pointed out, it was all stuff that could be done by a dev with only the basic Sitecore training, which as there's a short supply of devs in the world, we can potentially make better use of who does what.
Extending and implementing cloud architectures with Rob Habraken
After one talk on cloud the day before I almost gave this one a miss, but I'm glad I didn't.
Rob gave us some of his learning's and things to look out for. As the the previous session the theme of Sitecore 9 becoming far more complex came up and he had some interesting takes on it:
- Use what you need, disable roles that you don't. I see plenty of Sitecore customers not making use of all the features, and when your in a microservice architecture it does raise the question of why even have this stuff turned on. If you don't use marketing automation then you don't need the role running. It's just costing money to do nothing.
- Scale down when your not using resource. Unlike a VM web apps can not be turned off so they always cost money. You can delete and recreate, but that's a pain. Instead set up a pipeline to scale them to the lowest resource setting when not being used.
- He went on to discuss and show how we can use azure functions and logic apps to implement our code rather than building into the main Sitecore project. However you should be careful overdoing it as it can become complex quickly and it's easy to end up with a massive unorganised list of individual azure functions.
Automated personalisation with Chris Nash and Niels Kuhnel
Chris and Niels pointed out the flaw in Sitecores reporting on personalised content. How do we know the rate each converts to a goal at? There's the A/B Test report's but that's not quite the same thing.
They went on to show how they had started measuring the display impressions and click through on personalised content. Then linking the results collected in the reporting db up to a Power BI dashboard.
Sitecore identity: A new Sitecore authentication mechanism with Himadri Chakrabarti
Himadri gave us a look at the new Identity Server framework in Sitecore 9.1:
- Identity server 4 framework
- Still uses old asp net membership provider underneath
- Can work with sub providers like Azure
Measure if you want to go faster with Jeremy Davis
Jeremy was in the situation where a site they were developing would have TV adverts during one of the most watch programs on British TV. Naturally he got scared and went looking for tools to help with performance. He told us about two of them:
- Sitecore debug tool in experience editor showing the time it takes for components to load.
- Using Visual Studio debugger to monitor processor usage and memory usage.
Both of these tools are very good at pointing you in the direction of smelly code and the best part is you already have them.
Unfortunately it's the kind of demo that really doesn't convert to text to write here.
We released JSS, you'll never guess what happened next with Adam Weber & Kam Figy
Adam and Kam showed us JSS working with SXA and Sitecore Forms. As mentioned before I don't know much about JSS but after this talk I'm convinced I definitely need to.
Right now it doesn't sound like I would make a site using it, but it could definitely be the future of how we build sites.
The stand out thing is being able to keep your Sitecore install unmodified which would essentially lead us to a real SAAS solution where a Sitecore instance could be spun up from the marketplace and then all other functionality added through server-less functions and a headless front end.