The other day someone told me .net was slow to get something built, and to be fair to the person I can see why he would have thought that. Most of his interaction with .net projects have been on complex with large enterprise applications that often have integrated multiple other applications.
However, I would maintain that .net is a framework that is actually really fast to develop on and that what he had perceived as being slow was the complexities of a project rather than the actual coding time.
In fact, I would say it's so fast to get something built in it, it actually becomes the fastest thing to develop a prototype in. Here are my top reasons why.
ASP.NET Core
ASP.NET Core inherits all the best bits from the ASP.NET Framework that came before it, giving the framework almost 20 years of refinement since its original release in 2002. The days of WebForms in the original ASP.NET are now long behind us and we now have the choice of building web applications with either MVC or Razor Pages.
Razor provides the perfect combination of a view language providing helpers to render your html without limiting what can be done on the front end. How you code your HTML is still completely up to you, the helpers just provide features like binding that make it even faster to do.
Another great thing about .Net core over that which came before it, is its platform independent. Rather than being confined to just Windows, you can run it on Mac or Linux too.
Great starter templates
What kicks of a great prototype project is starting with great templates, and ASP.NET Core has a bunch.
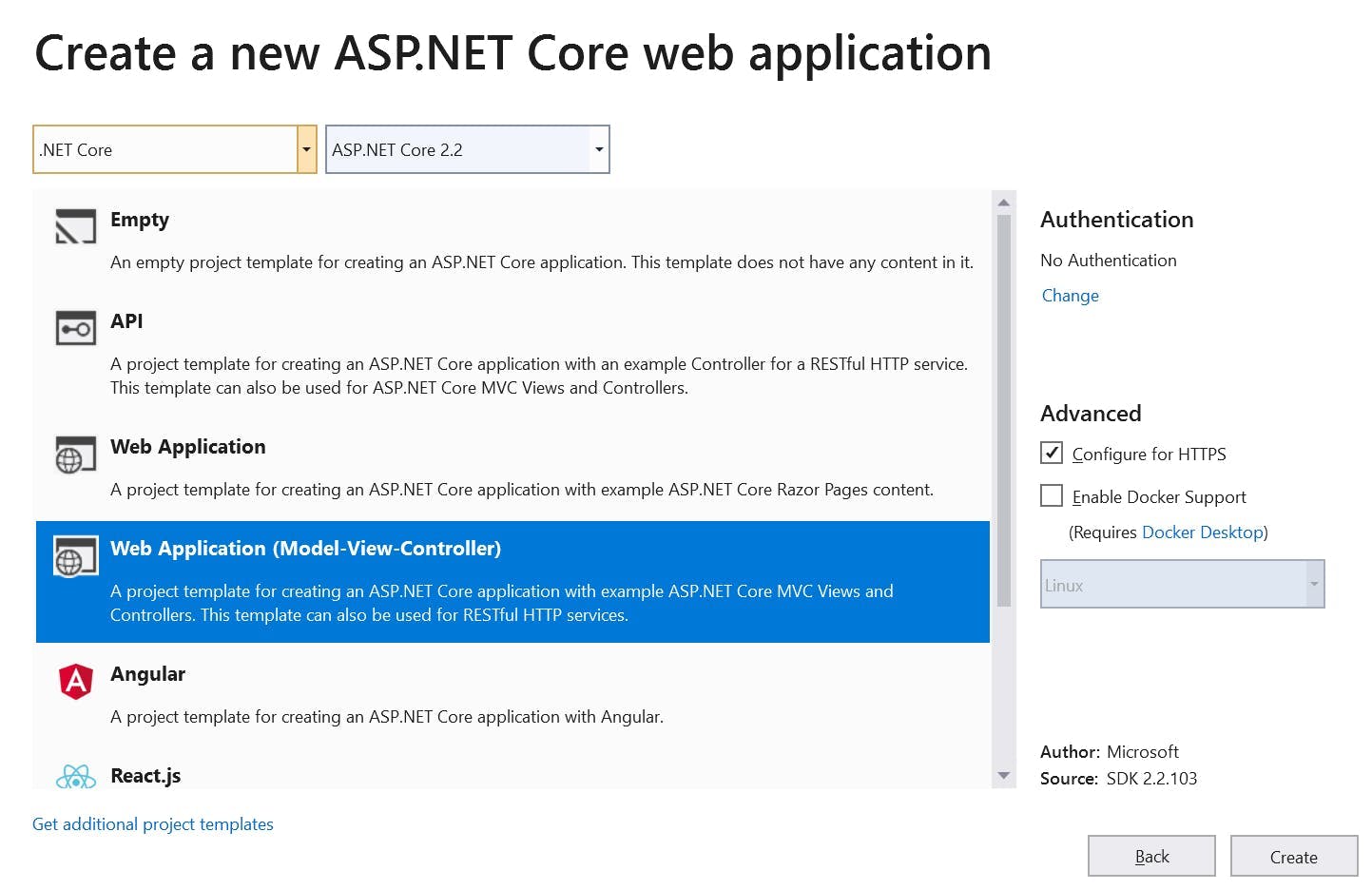
As already mentioned, you can build a Web Application with either Razor Pages or MVC, but the templates also provide you with the base for building an API, Angular App, React.js or React.js and Redux or you can simply create an Empty application.
My preference is to go for MVC as it's what I'm the most familiar with and a key thing for rapidly building a prototype is that you develop rapidly. The idea is to focus on creating something new and unique, not learn how to develop in a new framework.
The MVC Web Application gives you a base site to work with a few pages already set up, bootstrap and jQuery are already included so you start right at the point of working on your logic rather than spending time doing setup.
SQL Server and EF Core
I've always been a bit of a database guy. I'm not sure why, but its a topic that has always just made sense to me, and despite being a topic that can get quite complex, the reasons behind it being complex always feel logical.
When it comes to building a prototype though there are two aspects which make storage with .net core super simple.
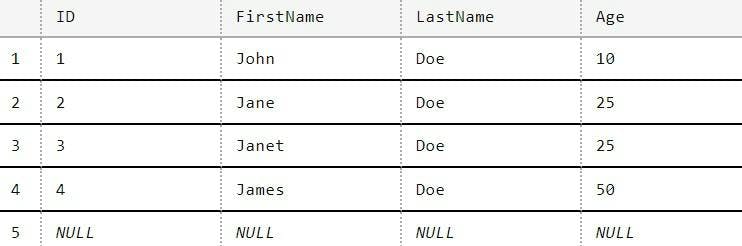
Firstly, Entity Framework Core (EF Core) means you don't really need to know any SQL or spend any time writing it. It helps if you do, but at a minimum all you need to be doing is creating a model in your code, adding a few lines for a DB context that tells EF.Core that a model is a table and how they relate. Then turn on migrations and you're done. When you run the application, the DB gets created for you and each time you change your model, you just add another migration and the next time the application runs the application the DB schema gets updated.
Querying your DB is done by writing LINQ queries against your entity framework model, allowing you to have next to no understanding of SQL and how the DB works. Everything is just done by magic for you.
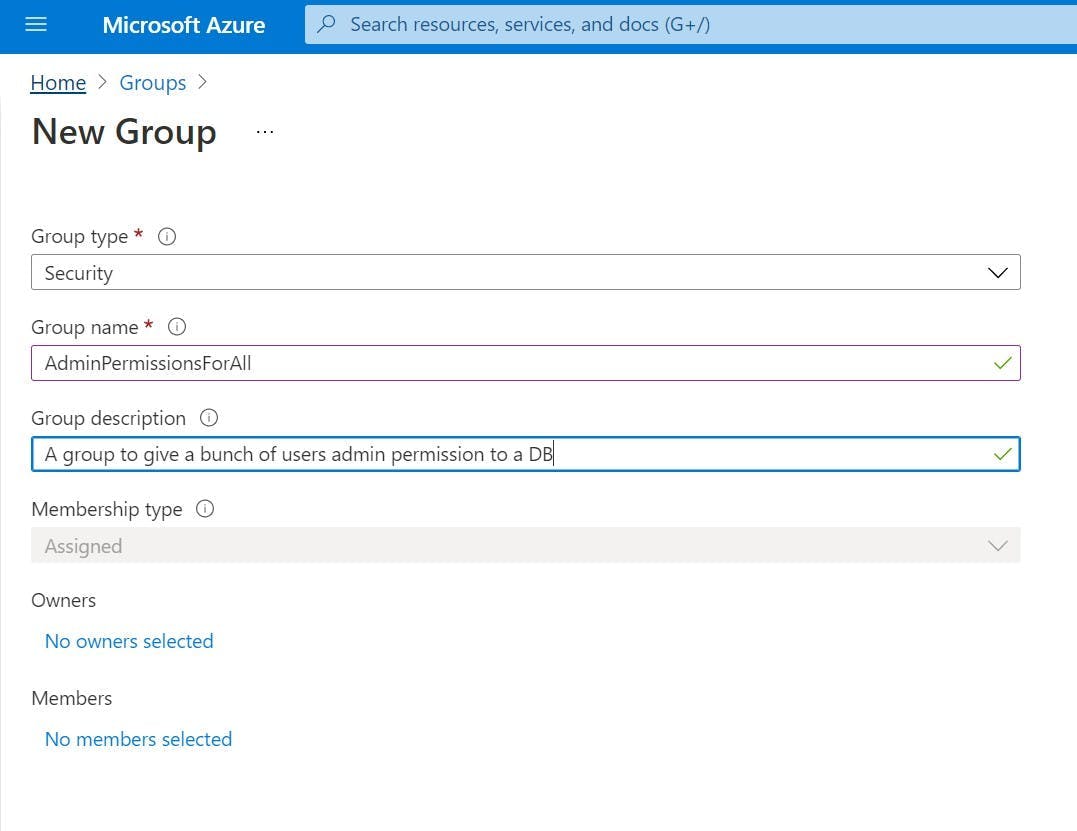
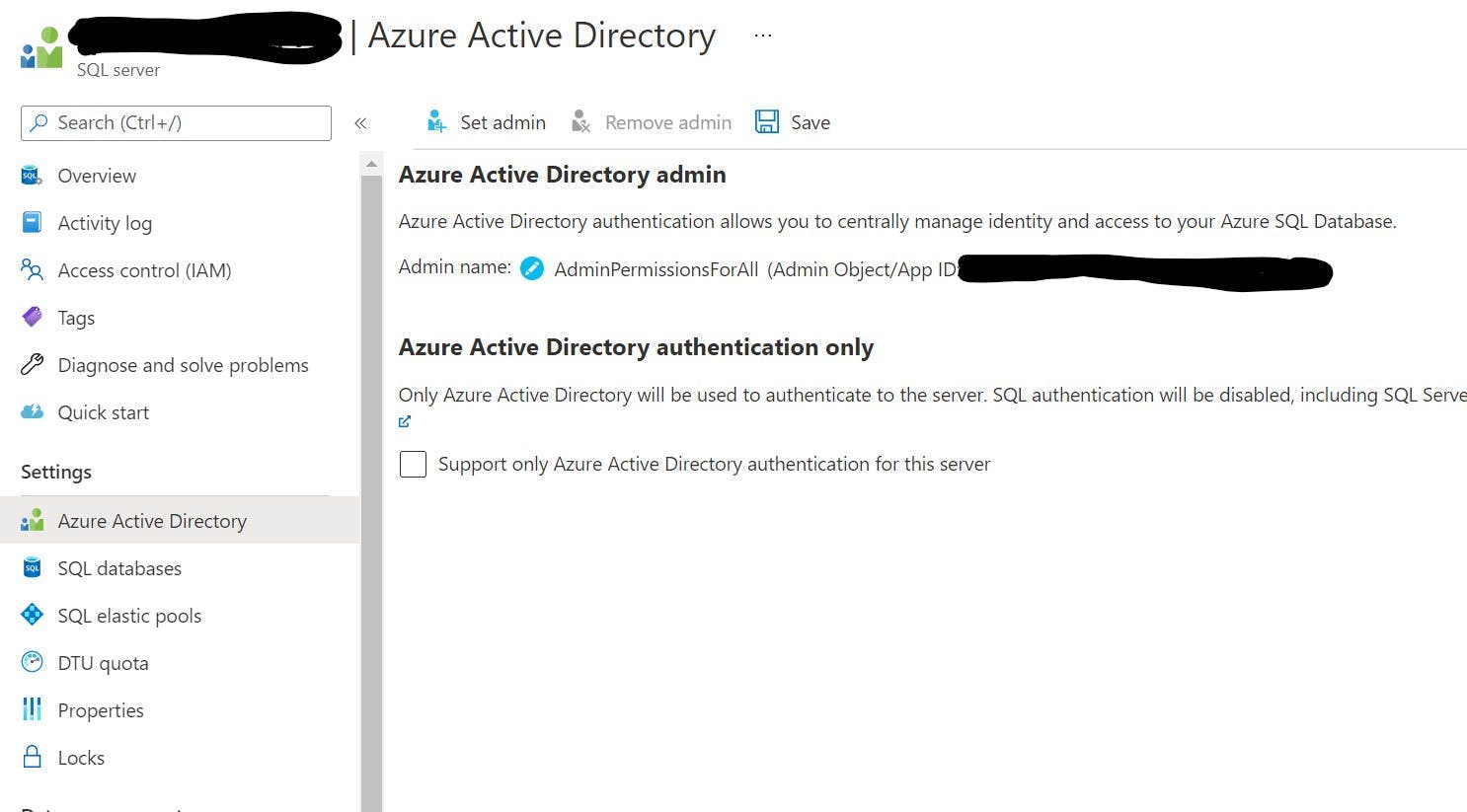
The second part is SQL Server and its different versions. Often when you think of SQL Server you think of the big DB engine with its many many components that you install on a server or your local machine but there's two others which are even more important. LocalDB and Azure SQL.
LocalDB is an option that can be installed as part of Visual Studio. No separate application is needed or services to be running in the background. It is essentially the minimum required to start the DB engine to be used for development purposes. In practical terms this means when you start your application EF.Core can run off a LocalDB which didn't require any setup, but as far as your application in concerned it is no different than working with any other version of SQL Server.
Azure SQL as the name implies is SQL Server on Azure. The only thing I really need to say about this is that you can swap LocalDB and Azure SQL with ease. They may be different but as far as your prototype is concerned, they are the same.
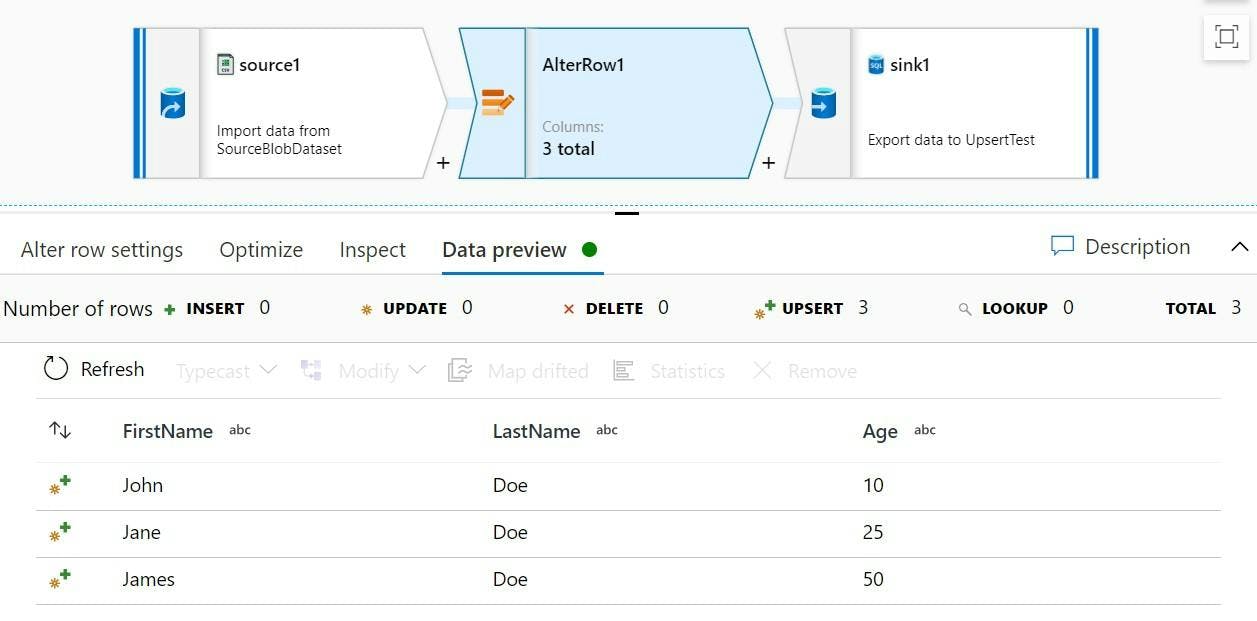
Scaffolding
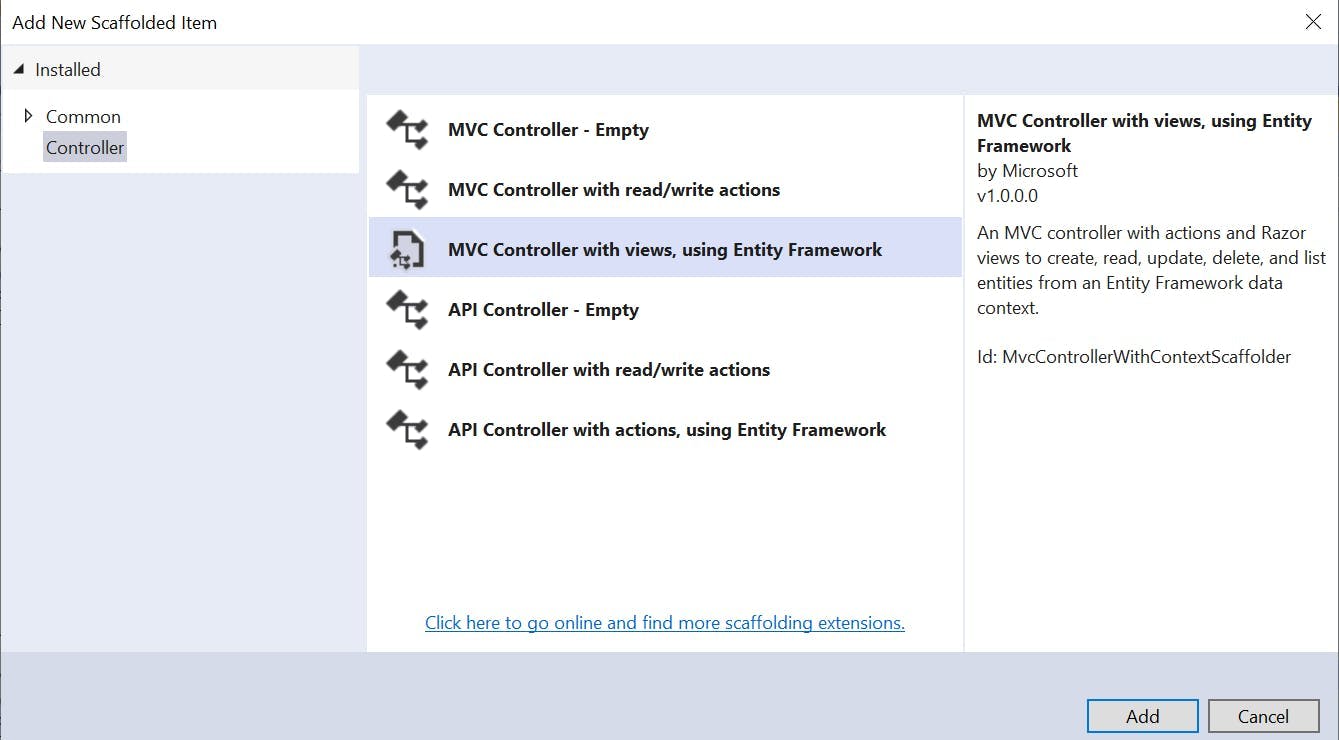
The only thing quicker than writing code is having someone else do it for you. So we've created our application from a template, added a model which generated our database and now its time to create some pages. Well the good news is it's still not time to write much code because Visual Studio can scaffold out pages based on our model for us!
Adding a controller to our project in Visual Studio gives us some options on what should be generated for us, one of which is MVC Controller with views, using Entity Framework. What that means is given a model it will create controllers and views for listing items, creating them, editing them and deleting them. No coding by us required!
Now it's unlikely that is exactly what you're after, but it's generally a good starting place and deleting code you don't need is far quicker then writing it.
Azure
Lastly there is Azure. You may have spotted a theme to all these points and that is they all remove any effort required to do any setup and instead focus on building your own logic, and this point is no different.
I remember a time, when if I wanted a server to put an application on, I had to request it, and then wait a while. What I would get back would either be a server that already had resources running on it, or a blank server that would need applications installed on it. e.g. SQL Server or .Net Framework. IIS wouldn't have been configured and it would be a number of hours before my application would be running.
With Azure you don't even really need to leave Visual Studio. From the publish dialog box you can create a new App Service and DB, and then publish. All the connection strings are sorted out for you. There are service plans which cost next to nothing, a domain is configured for you and at the end of the publish the website opens and is working. The whole process has taken less than 10 minutes.