Data Factory: How to upsert a record in SQL
When importing data to a database we want to do one of three things, insert the record if it doesn't already exist, update the record if it does or potentially delete the record.
For the first two, if your writing a stored procedure this often can lead to a bit of SQL that looks something like this:
1IF EXISTS(SELECT 1 FROM DestinationTable WHERE Foo = @keyValue)2BEGIN3 UPDATE DestinationTable4 SET Baa = @otherValue5 WHERE Foo = @keyValue6END7ELSE8BEGIN9 INSERT INTO DestinationTable(Foo, Baa)10 VALUES (@keyValue, @otherValue)11END
Essentially an IF statement to see if they record exists based on some matching criteria.
Data Factory - Mapping Data Flows
With a mapping data flow, data is inserted into a SQL DB using a Sink. The Sink let's you specify a dataset (which will specify the table to write to), along with mapping options to map the stream data to the destination fields. However the decision on if a row is an Insert/Update/Delete must already be specified!
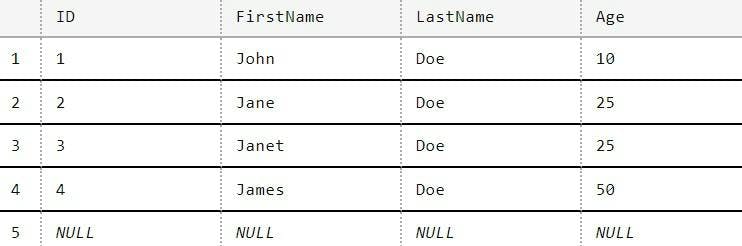
Let's use an example of some data containing a persons First Name, Last Name and Age. Here's the table in my DB;
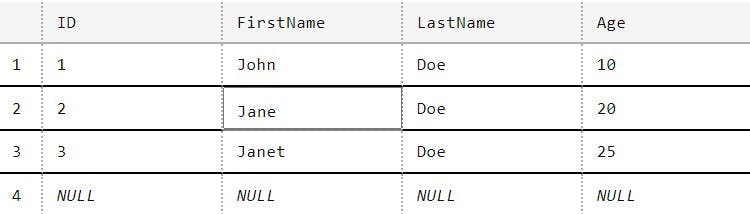
And here's a CSV I have to import;
1FirstName,LastName,Age2John,Doe,103Jane,Doe,254James,Doe,50
As you can see in my import data Jane's age has changed, there's a new entry for James and Janet doesn't exist (but I do want to keep here in the DB). There's also no ID's in my source data as that's an identity created by SQL.
If I look at the Data preview on my source in the Data Flow, I can see the 3 rows from my CSV, but notice there is also a little green plus symbol next to each one.
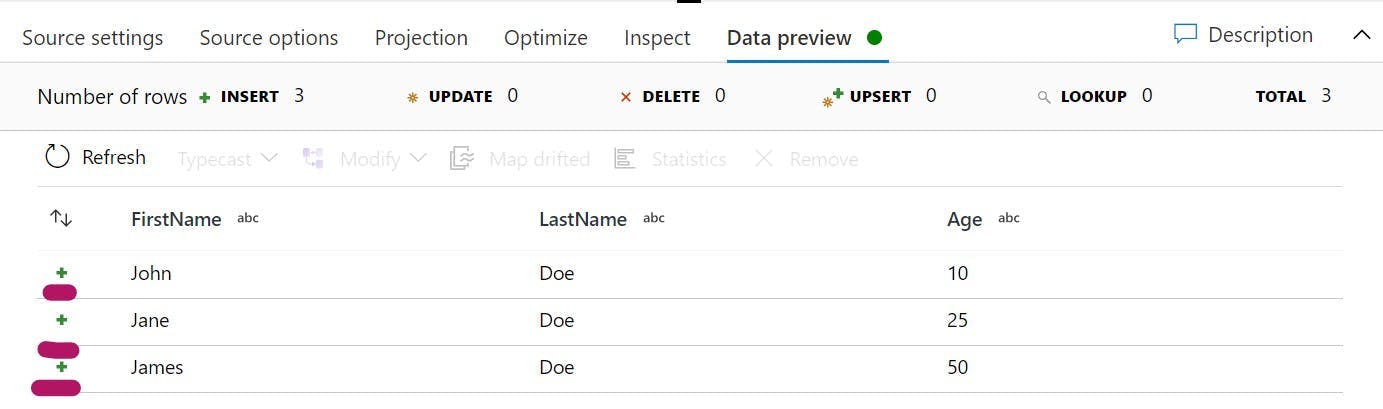
This means that they are currently being treated as Inserts. Which while true for one of them is not for the others. If we were to connect this to the sink it would result in 3 new records being added to the DB, rather than two being updated.
To change the Insert to an update you need an alert row step. This allows us to define rules to state what should be an insert and what should be an update.

However to know if something should be an insert or an update requires knowledge of what is in the DB. To do that would mean a second source, followed by a join on First Name/Last Name and then conditions based on which rows have an ID from the DB or not. This all seems a bit needlessly complicated, and it is.
Upsert
When using a SQL sink there is a 4th option for what kind of method should be used and that is an Upsert. An upsert will result in a SQL merge being used. SQL Merges take a set of source data, compare it to the data already in the table based on some matching keys and then decide to either update or insert new records based on the result.
On the sink's Settings tab untick Allow insert and tick Allow upsert. When you tick Allow upsert properties for Key columns will appear which is where you specify which columns should be used as a key. For me this is FirstName and LastName.
If you don't already have an Alter Row step it will warn you that this is missing.
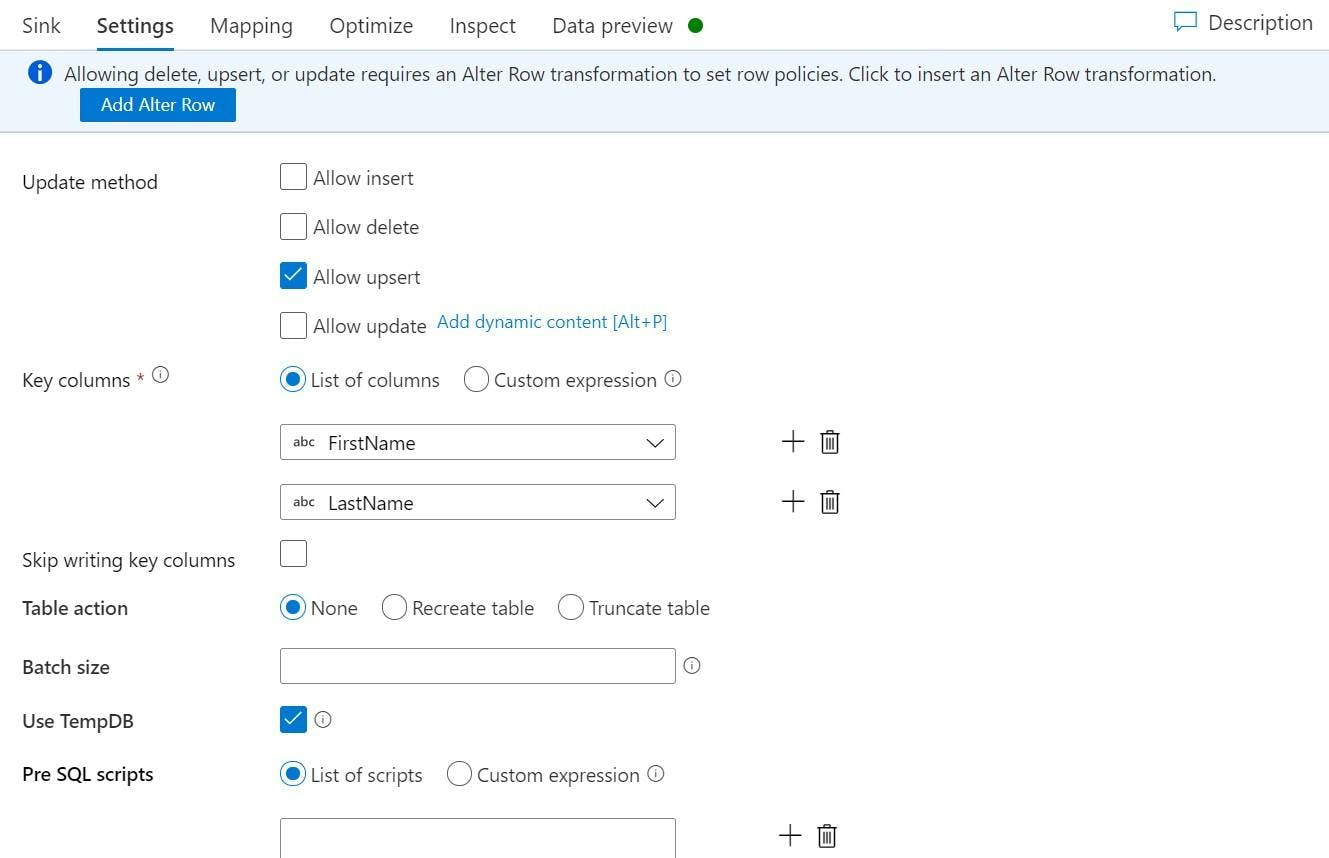
Even though we are only doing what equates to a SQL merge, you still need to alter the rows to say they should be an upsert rather than an insert.
As we are upserting everything our condition can just be set to return true rather than analysing any row data.
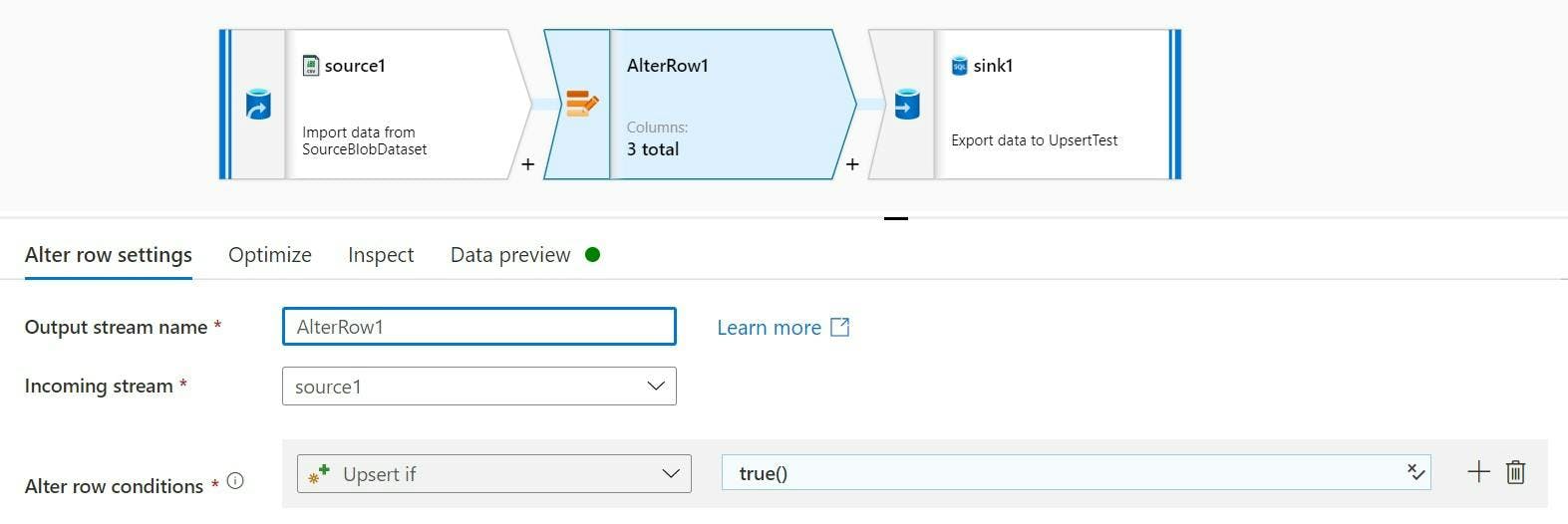
And there we have it, all rows will be treated as an upsert. If we look at the Data preview we can now see the upsert icon on each row.
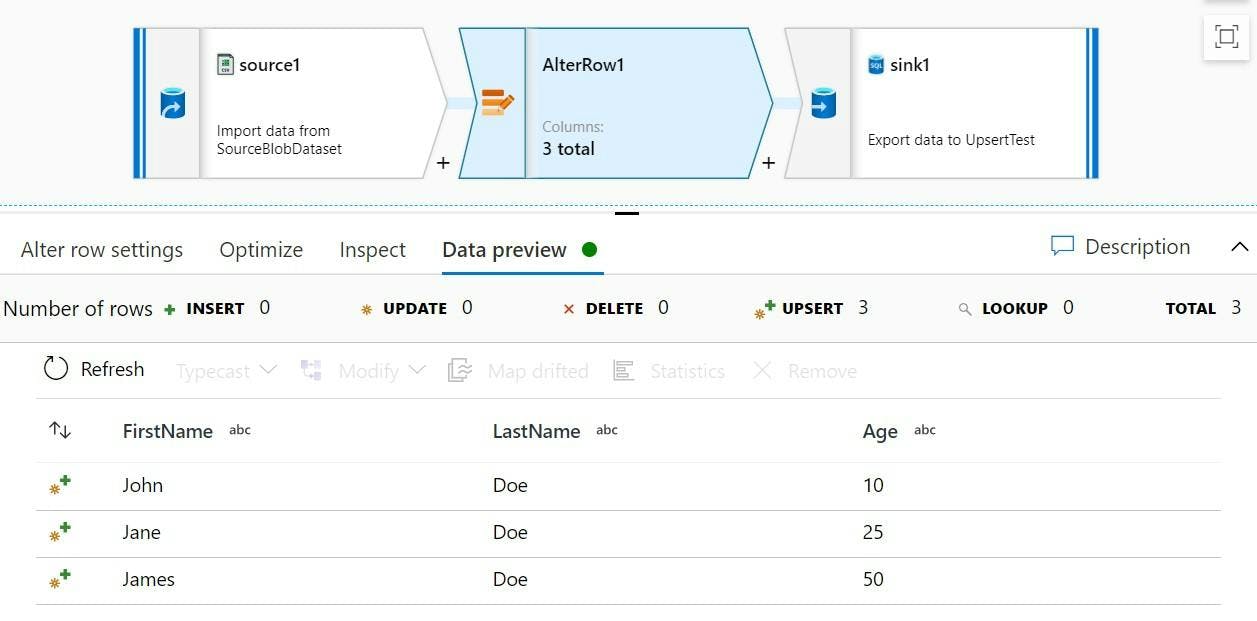
And if we look at the table after running the pipeline, we can see that Janes age has been update, James has been added and John and Janet stayed the same.