Reducing the size of Sitecore Master DB
When it comes to Sitecore development, an issue every developer has likely experienced is the size of the databases in relation to the size of their hard disk. In an ideal world production DBs would contain production data, test environments would have data ideally suited for testing and developer workstation would have the minimum required to develop the solution.
In reality though, I think most people have the experience of everything being a copy from production. This ends up being the case due to a clients requirements that UAT needs to looks the same as prod, QA needs prod content to replicate a bug and although critical Sitecore items may have been serialized, not having any content in your local makes it a bit hard to dev.
When a website is new and doesn't have much content this isn't a huge issue, but when you inherit one 5 years old with a 25gb DB, things start to become a problem. Not only is the hard disc space required an issue, but just setting a new developer up takes hours from download times.
After getting a new laptop and being faced with the challenge of needing to copy multiple DBs (and not even having enough space to back them up on my existing machine), I decided to finally do something about reducing the size of them,
Removing old item versions
Having a history of item versions is a great feature for content editors, however as a dev I don't really need them on my local. They also hold references to media items that aren't used any more.
This Sitecore Powershell script from Webbson does exactly that and even lets your specify how many version you want to keep. I went for 1.
1<#2 This script will remove old versions of items in all languages so that the items only contains a selected number of versions.3#>45$item = Get-Item -Path "master:\content"6$dialogProps = @{7 Parameters = @(8 @{ Name = "item"; Title="Branch to analyse"; Root="/sitecore/content/Home"},9 @{ Name = "count"; Value=10; Title="Max number of versions"; Editor="number"},10 @{ Name = "remove"; Value=$False; Title="Do you wish to remove items?"; Editor="check"}11 )12 Title = "Limit item version count"13 Description = "Sitecore recommends keeping 10 or fewer versions on any item, but policy may dictate this to be a higher number."14 Width = 50015 Height = 28016 OkButtonName = "Proceed"17 CancelButtonName = "Abort"18}1920$result = Read-Variable @dialogProps2122if($result -ne "ok") {23 Close-Window24 Exit25}2627$items = @()28Get-Item -Path master: -ID $item.ID -Language * | ForEach-Object { $items += @($_) + @(($_.Axes.GetDescendants())) | Where-Object { $_.Versions.Count -gt $count } | Initialize-Item }29$ritems = @()30$items | ForEach-Object {31 $webVersion = Get-Item -Path web: -ID $_.ID -Language $_.Language32 if ($webVersion) {33 $minVersion = $webVersion.Version.Number - $count34 $ritems += Get-Item -Path master: -ID $_.ID -Language $_.Language -Version * | Where-Object { $_.Version.Number -le $minVersion }35 }36}37if ($remove) {38 $toRemove = $ritems.Count39 $ritems | ForEach-Object {40 $_ | Remove-ItemVersion41 }42 Show-Alert "Removed $toRemove versions"43} else {44 $reportProps = @{45 Property = @(46 "DisplayName",47 @{Name="Version"; Expression={$_.Version}},48 @{Name="Path"; Expression={$_.ItemPath}},49 @{Name="Language"; Expression={$_.Language}}50 )51 Title = "Versions proposed to remove"52 InfoTitle = "Sitecore recommendation: Limit the number of versions of any item to the fewest possible."53 InfoDescription = "The report shows all items that have more than <b>$count versions</b>."54 }55 $ritems | Show-ListView @reportProps56}5758Close-Window
Removing unpublished items
After a few failed attempts at reducing the size of the DB's, I discovered that the content editors working on the website had seemingly never deleted any content. Instead that had just marked things as unpublishable. I can see the logic in this, but after 5+ years, they have a lot of unpublished content filling up the content tree.
Well if it's unpublished I probably don't need it on my local machine so lets delete it.
Here's a script I wrote, the first part removes items set to never publish. After running just this part I found lots of the content items had the item set to publish but the version set to hidden. The second part loops through versions on items and removes any version set to hidden. If the item has no version left then it is removed too.
123// Remove items set to never publish4Get-ChildItem -Path "master:\sitecore\content" -Recurse |5Where-Object { $_."__Never publish" -eq "1" } | Remove-Item -Recurse -Force -Confirm:$false67// Loop through items and remove versions set to never publish, then remove the item if it has no versions left8foreach($item in Get-ChildItem -Path "master:\sitecore\content" -Recurse) {910 $item11 foreach ($version in $item.Versions.GetVersions($true))12 {13 $version14 $version."__Hide version"15 if ($version."__Hide version" -eq "1" ) {16 $version| Remove-ItemVersion -Recurse -Confirm:$false17 }18 }1920 if ($item.Versions.GetVersions($true).count -eq 0) {21 $item | Remove-Item -Recurse -Force -Confirm:$false22 }23}
Remove dead links
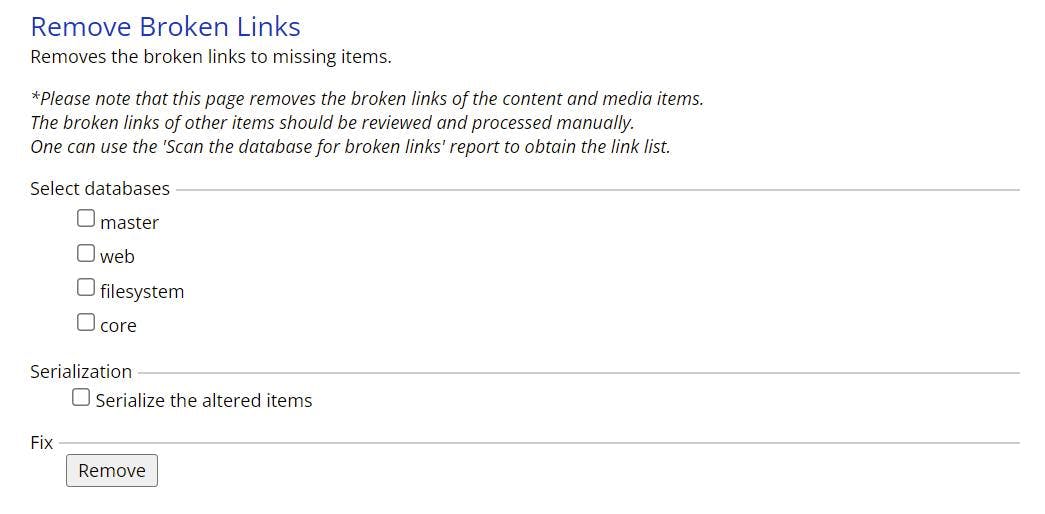
In the next step I rebuild the links DB, but I kept ending up with entries in the link table with target items that didn't exist. After a bit of searching I came across an admin page for clearing up dead links.
/sitecore/admin/RemoveBrokenLinks.aspx
With this page you can remove all those pesky dead links caused by editors deleting items and leaving the links behind.
Clean Up DBs
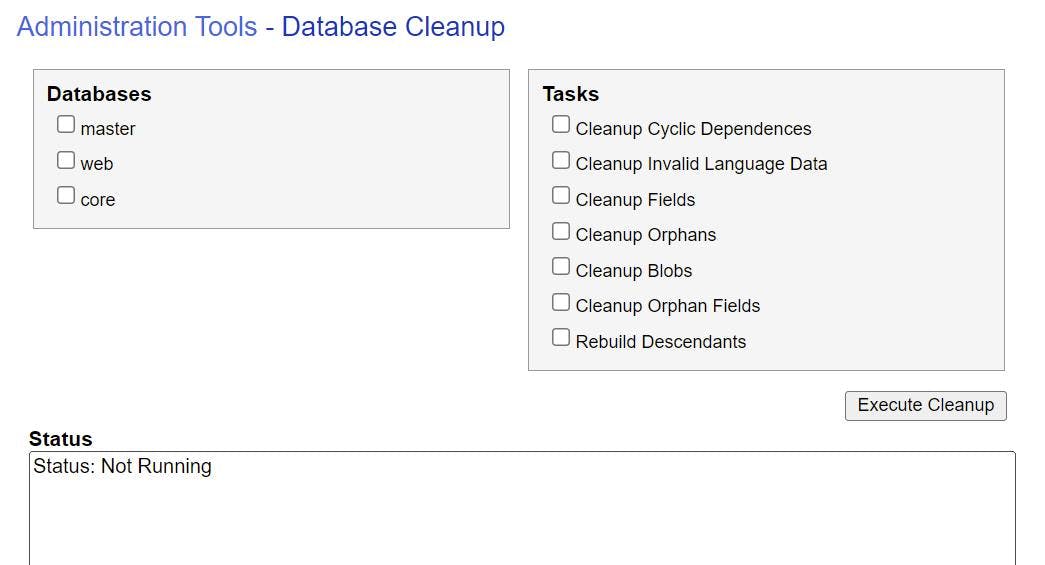
With our content reduced the DB's now need a clean up before we do anything else.
In the admin section there is a DB Cleanup page that will let you perform various tasks on the DB. I suggest doing all of these.
/sitecore/admin/DBCleanup.aspx
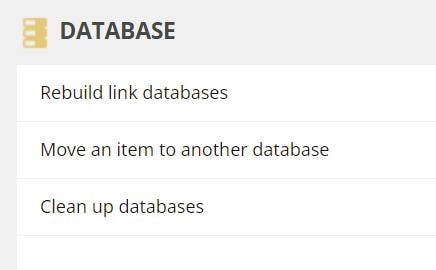
Once this is done navigate to the control panel and rebuild the link database. From the control panel you can also run the clean up database script, but it won't give you as much feedback.
/sitecore/client/Applications/ControlPanel.aspx?sc_bw=1
Remove unused media
With all the old versions/items/dead links removed and the DB's cleaned up its time to get rid of any unused media items. It's likely if you have a large DB that most of the space will be taken up by the media items. Fortunately with another PowerShell script we can removed any media that isn't linked too.
This PowerShell script is an adapted version of one by Michael West. You can find his version here https://michaellwest.blogspot.com/2014/10/sitecore-powershell-extensions-tip.html?_sm_au_=iVVB4RsPtStf5MfN
The main difference is I've been more aggressive and removed the checks on item owner and age.
1filter Skip-MissingReference {2 $linkDb = [Sitecore.Globals]::LinkDatabase3 if($linkDb.GetReferrerCount($_) -eq 0) {4 $_5 }6}78$items = Get-ChildItem -Path "master:\sitecore\media library" -Recurse |9 Where-Object { $_.TemplateID -ne [Sitecore.TemplateIDs]::MediaFolder } |10 Skip-MissingReference1112if($items) {13 Write-Log "Removing $($items.Length) item(s)."14 $items | Remove-Item15}
Shrink databases
Lastly through SQL management studio, shrink your database and files to recover unused space you hopefully now have from removing all of that media.
In my case I was able to turn a 20+ GB database into a 7 GB database by doing these steps.
If your local is running with both web and master DB, you should now do a full publish. The item versions which are published should stay exactly the same as we only removed items set to not publish. You should however get a reduction in your web DB from the media items being removed.