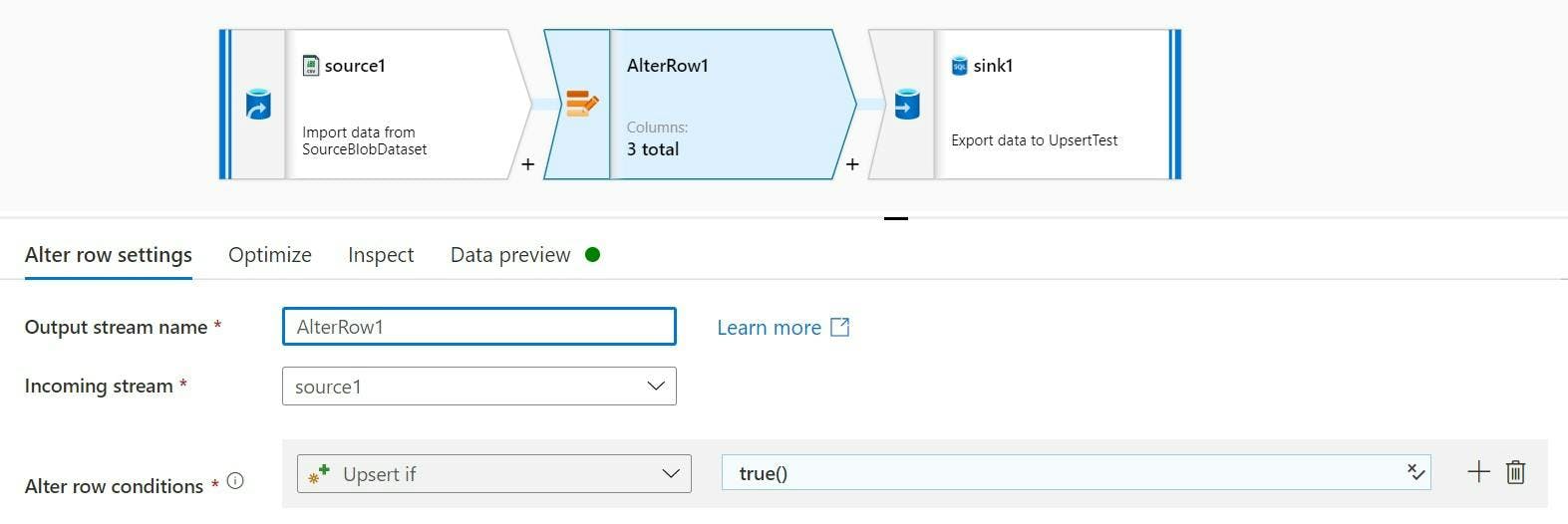
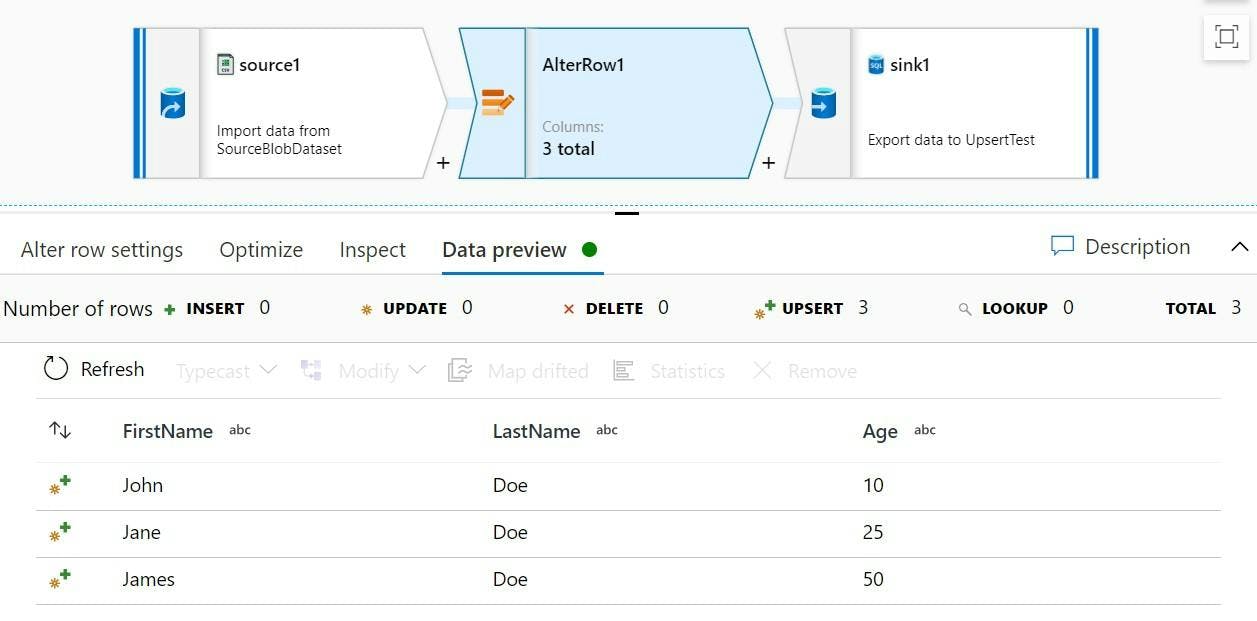
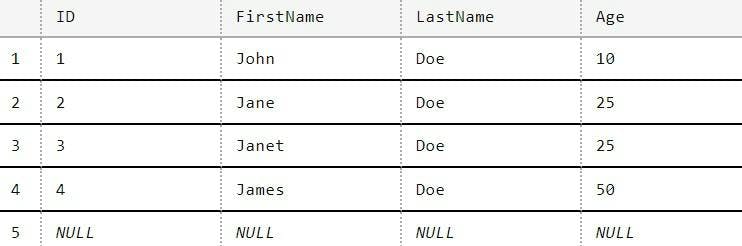
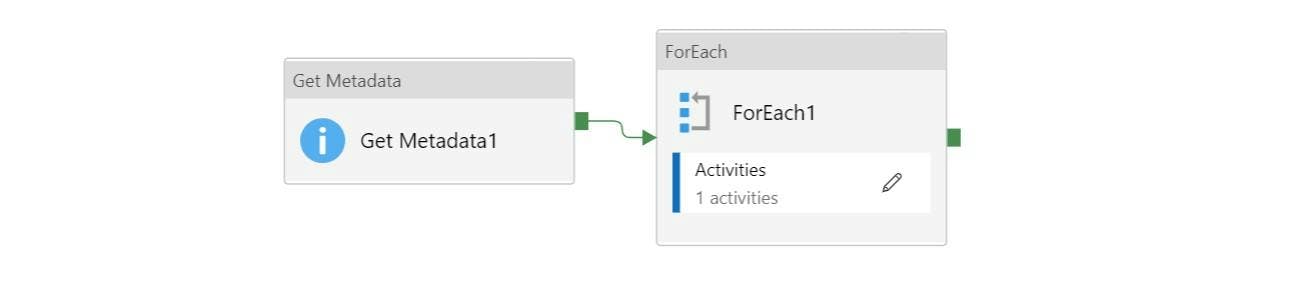
Azure Data Factory: Date formats when working with XML in Data Flows
If there was one thing you could guarantee would always go wrong when importing data it's date formats. Some countries like to show dates as dd/MM/yyyy others prefer MM/dd/yyyy and despite formats like yyyy-MM-dd being a thing in programming for a very long time, people seem to still create files with these ambiguous formats.
I found finding out how to specify what format the date is in within a flat file was not obvious. If you go to the dataset item for a XML file, unlike other formats it's missing the schema tab.
This wasn't overly surprising as I've come to find when using Datasets in a Mapping Data Flow half the time it seems to ignore any schema definition, or if you use wildcard paths it even seems to ignore all the path settings on the dataset.
Within the Data Flow, the source has a projection tab which will import a schema from your xml file. If your data looks like a date, then this will hopefully set the data type to date. One thing I found was having data in dd/MM/yyyy resulted in a format of string rather than date. Annoyingly unless you want to start manually editing the script the UI generates, there's no way of fixing the projection.
Assuming you have a date as the data type this is a good start, but I then found when I ran my data flow which had dates in dd/MM/yyyy, the date field was blank! So it definitely knows it's a date and not a string, but it's doesn't like the format so it's ignored the data.
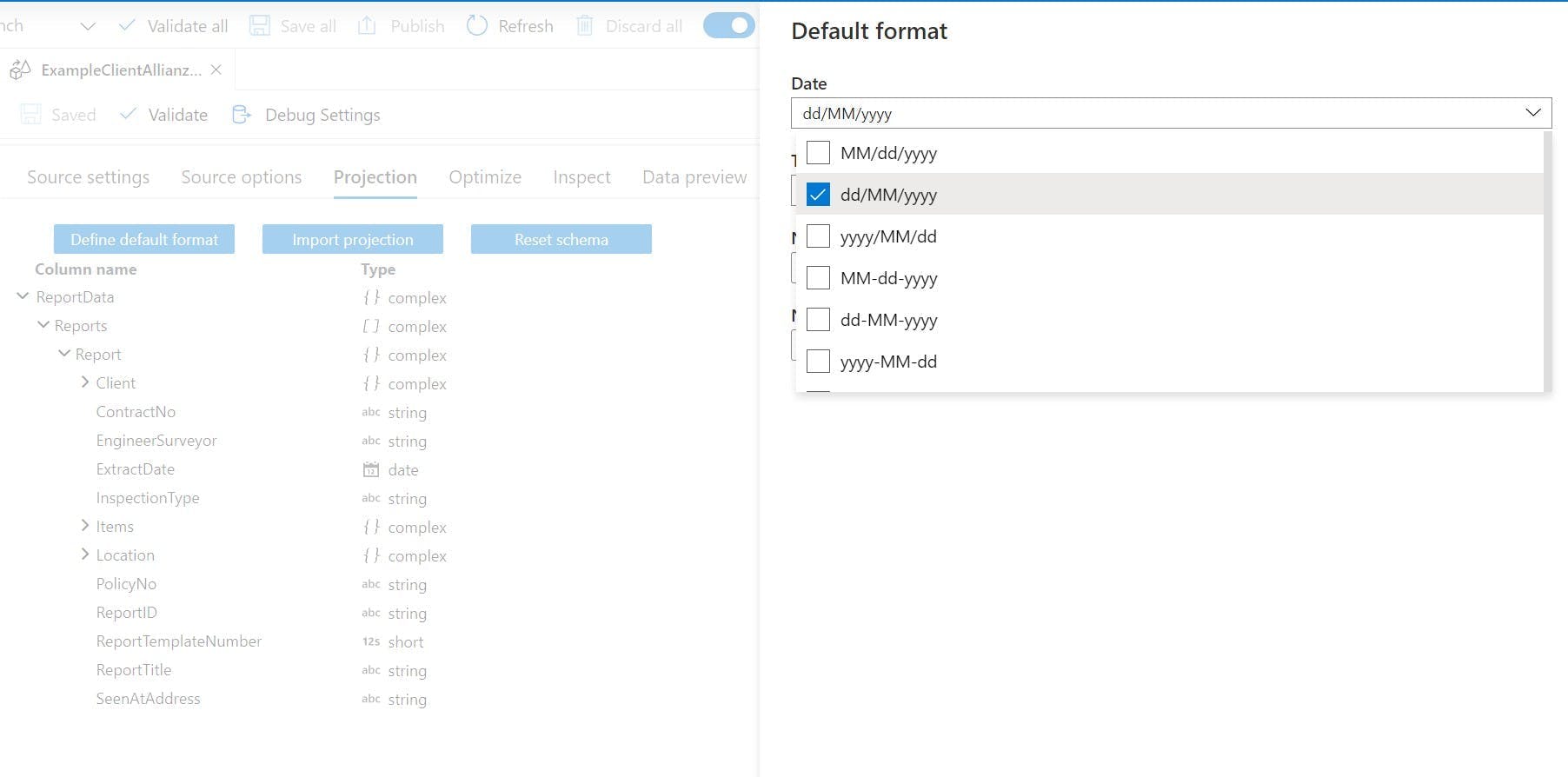
Back on the projection tab of the source there is another button "Define default format". This will open a side panel where you can set what format your dates, times, whole numbers and fractions will be in. Once I had set this, my dates started feeding through.