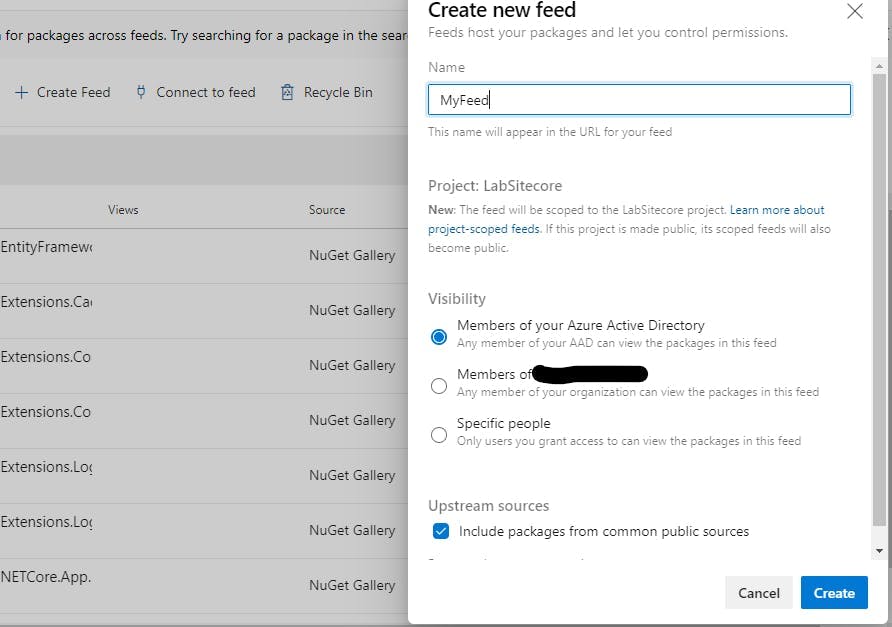
Deploying a SQL DB with Azure Pipelines
Normally when I work with SQL Azure I handle DB schema changes with Entity Framework migrations. However if you using Azure Functions rather than Web Jobs it seems there's a number of issues with this and I could not find a decent guide which resulted in a working solution.
Migrations isn't the only way to release a DB change though. SQL Server Database projects have existed for a long time and are a perfectly good way of automating a DB change. My preference to use EF Migrations really comes from a place of not wanting to have an EF model and a separate table scheme when they're essentially a duplicate of each other.
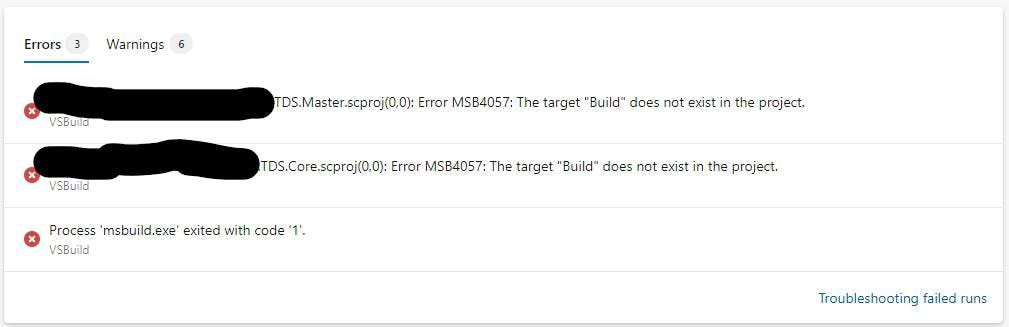
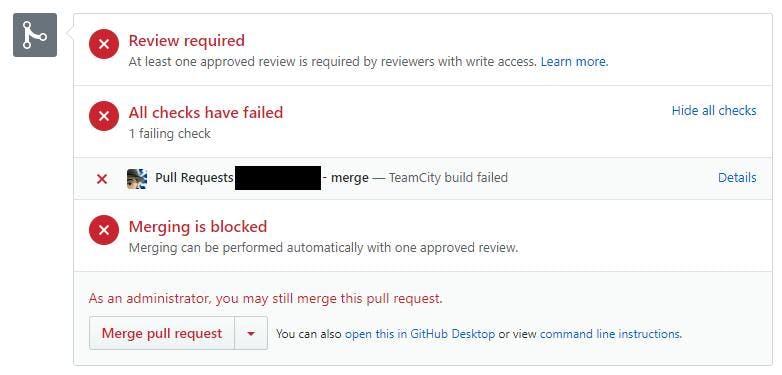
Trying to find out how to deploy this through Azure Devops Pipelines however was far harder than I expected (my expectation was about 5 mins). A lot of guides weren't very good and virtually all of them start with Click new pipeline, then select Use the classic editor. WAIT Classic Editor on an article written 3 months ago!?!?! Excuse me while I search for a solution slightly more up to date.
Creating a dacpac file
High level the solution solution is to have a SQL Server Database project, use an Azure Pipeline to compile that to a dacpac file. Then use a release pipeline to deploy that to the SQL Azure DB.
I'm not going to go into any details about how you create a SQL Server Database project, its relatively straightforward, but the one thing to be aware of is the project needs to have a target platform of Microsoft Azure SQL Database otherwise you'll get a compatibility error when you try to deploy.
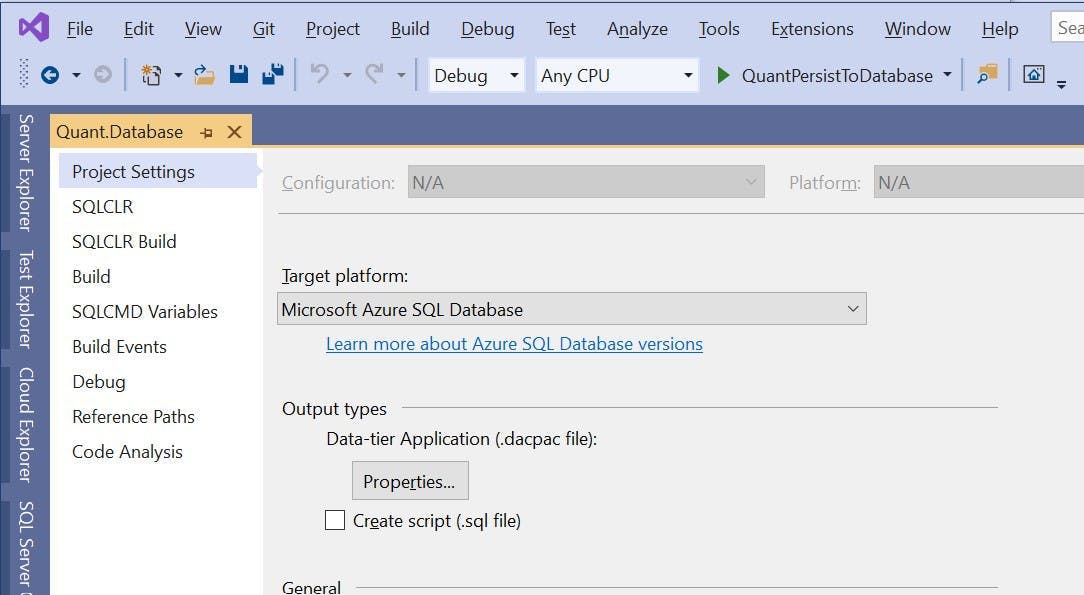
Building a SQL Server Database project in Azure Devops
To build a dacpac file create a new pipeline in Azure Devops (the yaml kind), select your repo and get yourself a blank configuration file. Also at this point make sure your code is actually in the repo!
The configuration I used looks like this; I've included notes in the code to explain what's going on.
1# The branch you want to trigger a build2trigger:3- master45pool:6 vmImage: "windows-latest"78variables:9 configuration: release10 platform: "any cpu"11 solutionPath: # Add the path to your Visual Studio solution file here1213steps:14 # Doing a Visual Studio build of your solution will trigger the dacpac file to be created15 # if you have more projects in your solution (which you probably will) you may get an error here16 # as we haven't restored any nuget packages etc. For just a SQL DB project, this should work17 - task: VSBuild@118 displayName: Build solution19 inputs:20 solution: $(solutionPath)21 platform: $(platform)22 configuration: $(configuration)23 clean: true2425 # When the dacpac is built it will be in the projects bin/configuation folder26 # to get into an artifact (probably with some other things you want to publish like an Azure function)27 # we need to move it somewhere else. This will move it to a folder called drop28 - task: CopyFiles@229 displayName: Copy DACPAC30 inputs:31 SourceFolder: "$(Build.SourcesDirectory)/MyProject.Database/bin/$(configuration)"32 Contents: "*.dacpac"33 TargetFolder: "$(Build.ArtifactStagingDirectory)/drop"3435 # Published the contents of the drop folder into an artifact36 - task: PublishBuildArtifacts@137 displayName: "Publish artifact"38 inputs:39 PathtoPublish: "$(Build.ArtifactStagingDirectory)/drop"40 ArtifactName: # Artifact name goes here41 publishLocation: container
Releasing to SQL Azure
Once the pipeline has run you should have an artifact coming out of it that contains the dacpac file.
To deploy the dacpac to SQL Azure you need to create a release pipeline. You can do this within the build pipeline, but personally I think builds and releases are different things and should therefore be kept separate. Particularly as releases should be promoted through environments.
Go to the releases section in Azure Devops and click New and then New release pipeline.
There is no template for this kind of release, so choose Empty job on the next screen that appears.

On the left you will be able to select the artifact getting built from your pipeline.
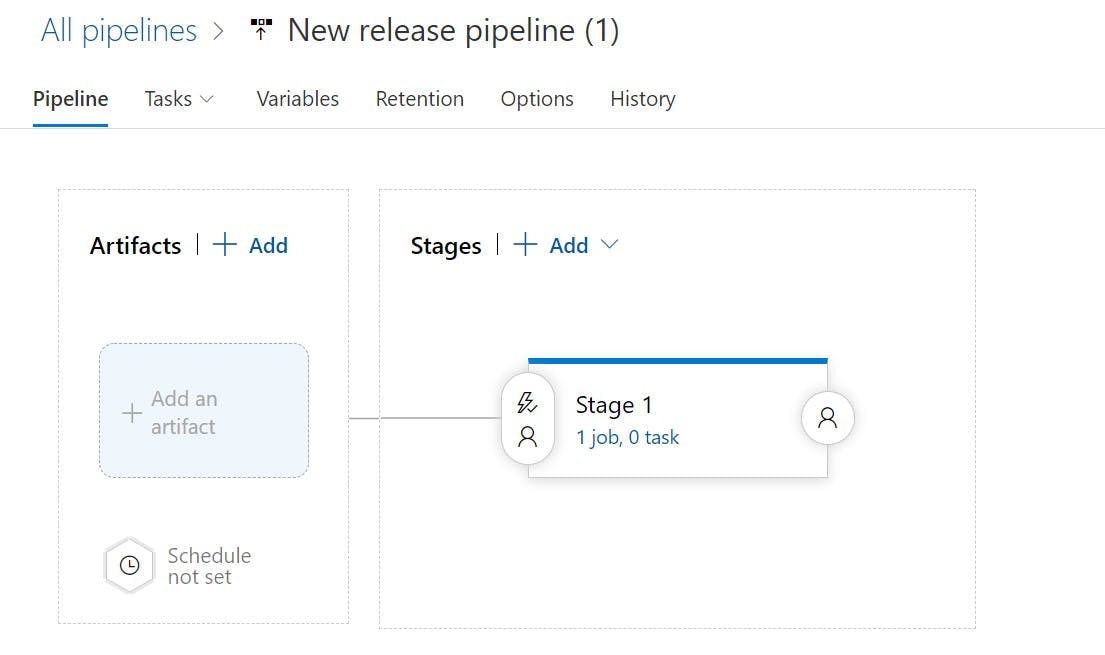
Then from the Tasks drop down select Stage 1. Stages can represent the different environments your build will be deployed to, so you may want to rename this something like Dev or Production.
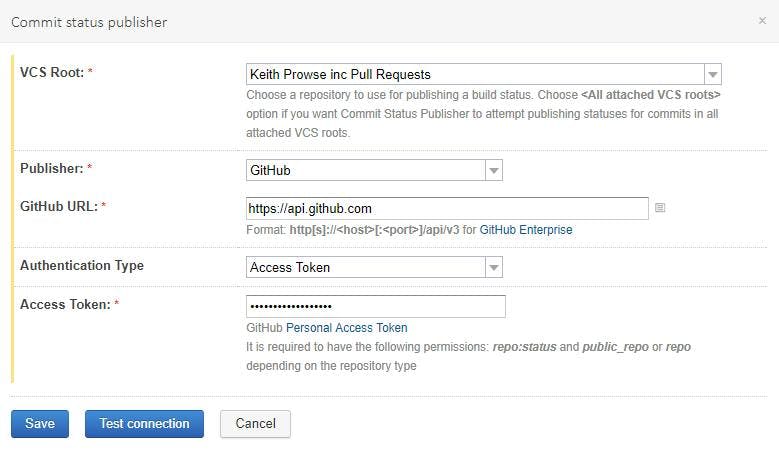
On Agent Job click the plus button to add a task to the agent job. Search for dacpac and click the Add button on Azure SQL Database deployment.
Complete the fields to configure which DB it will be deployed to (as shown in the picture but with your details).
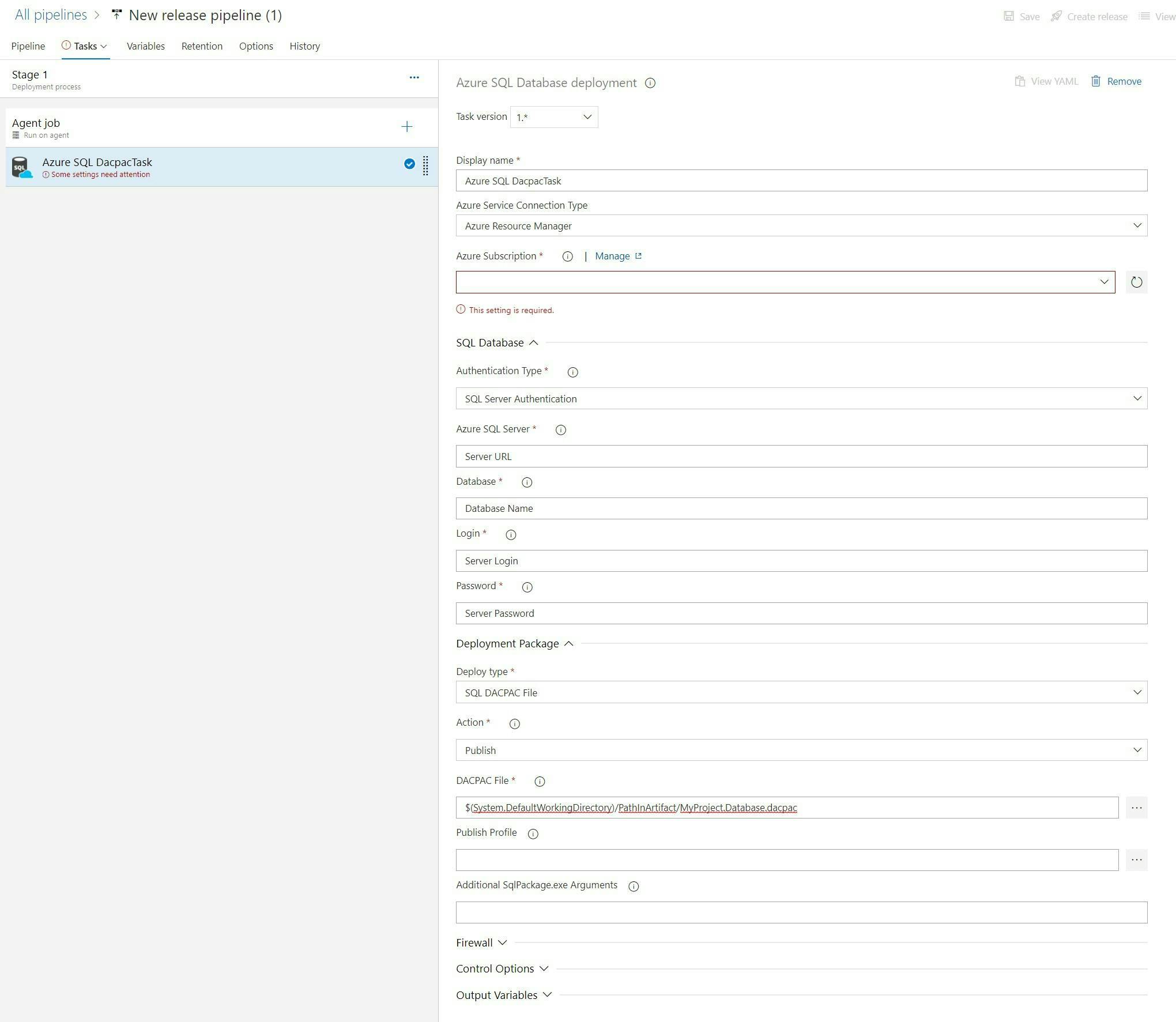
And that's it. You can now run the pipelines and your SQL Project will be deployed to SQL Azure.
Some other tips
On the Azure SQL Database deployment task there is a property called Additional SqlPackage.exe Arguments this can be used to specify things like should loss of data be allows. You can find the list of these at this url https://docs.microsoft.com/en-us/sql/tools/sqlpackage/sqlpackage?view=sql-server-ver15#properties
If you are deploying to multiple environments you will want to use variables for the server details rather than having them on the actual task. This will make it easier to clone the stages and have all connections details configured in one place.