
Adding Build Statuses to Pull Requests with TeamCity and GitHub
I'm always looking for ways to improve our build server setup and improve our overall efficiency. So a recent change I've made is to get Team City to start building pull requests and pushing the resulting status back to GitHub.
This improves our dev flow by eliminating the need to do any testing on a pull request if we can already see it will fail a build. Previously someone doing a code review would only find out once they've checked out the change and built it locally, or even worse after approving the request and then breaking the build.
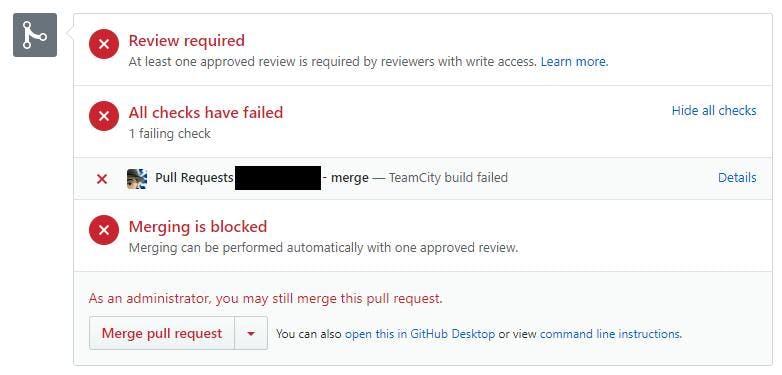
What's particularly good with this setup, is it's testing the resulting merge rather than just the branch being merged in.
Team City Setup
As this is covering a different scenario to our normal build processes which are focused on preparing a build version to be deployed, I set this up as a second build configuration on our projects.
Version Control Settings Root (VCS Root)
The VCS Root needs to be configured to fetch each pull request that is creating in GitHub. To do this, you will need to add a Branch specification which will tell Team City to monitor additional branches rather than just the default branch specified.
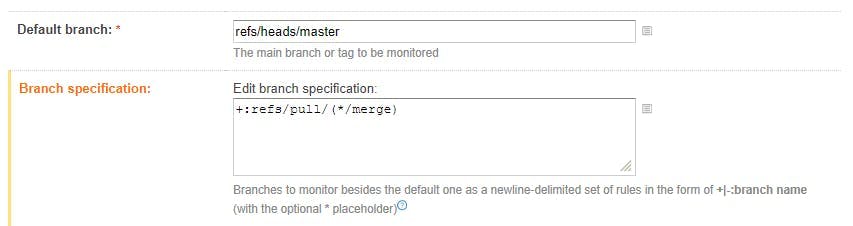
I'm using the branch specification +:refs/pull/(*/merge) .
This syntax is telling Team City to monitor references to pull for pull request, the * refers to any pull request, and the merge indicates that we only want to resulting merge of the pull request.
When you create a pull request in GitHub, this merge reference is automatically created for what the resulting merge would look like.
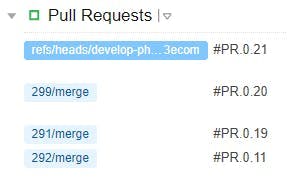
In the projects list, builds will now get labels indicating what they were for:
Build Steps
I created my build configurations by duplicating the existing ones we have that take care of creating builds to be passed onto Octopus Deploy for release. If you do this, it's important to remember to disable all the steps you no longer need.
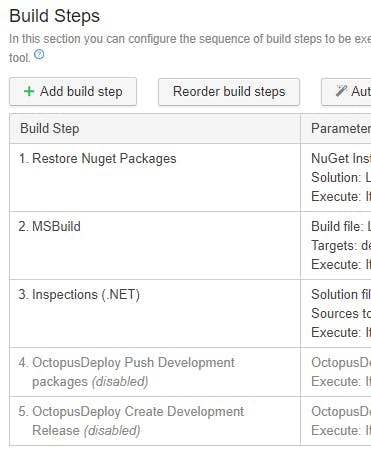
The less steps you have the quicker your build will run and the quicker the pull request will be updated with a status. Ideally you want the process to finish before someone starts doing a code review! Steps like running Inspections may prove counter productive if the builds are never finished on time.
Triggers
Having a build running automatically for your releases can be a drain on server resources, particularly if you never have any intention of actually doing a deploy for most of them. For this reason our builds are set to manual.
However for statuses to be of any use, they're going to need to be running automatically so that the status is ready for the code reviewer, so we need to add a VCS Trigger.

Build Features
To get Team City to start posting status updates back to GitHub we need to add a build feature. If your on a version of TeamCity prior between 7.1 and 10 then there is a plugin you can grab here https://github.com/jonnyzzz/TeamCity.GitHub. If your on a newer version of TeamCity. i.e. 10+ then the build feature is now built in and is called Commit status publisher. The built in version also has support for Bitbucket, Gerrit, GitLab, JetBrains Upsource and Visual Studio Team Services.
Add the build feature and fill in the config settings.
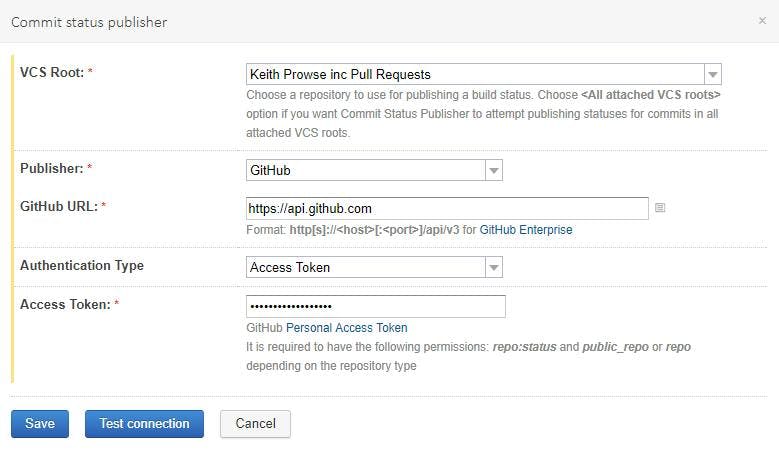
And that's it. Your pull requests will now automatically build and have the status sent back to GitHub.

Not only will you be able to see this status in GitHub, you'll also be able to click a details link to see the build. Useful in the event that it's failed and you want to see why.